1 爬虫
1.1 原理
(1)发送GET请求,获取HTML;
(2)解析HTML,获取目标信息;
(3)存储数据;
(4)重复第一步
1.2 工具
-
Requests:HTTP库,可以进行GET POST等
-
Selenium:可以定位页面中的各种元素,如输入框、按钮等,进行模拟登录等操作,可以先通过Selenium到所需网页,然后用BeautifulSoup、PyQuery等解析,缺点是很慢
得到的是已经渲染过的页面?
-
Splash:
-
BeautifulSoup:用于解析GET到的页面
-
PyQuery:用于解析GET到的页面
-
正则表达式re:用于解析GET到的页面
-
Scrapy:分布式爬虫框架
-
浏览器F12开发者工具:右键查看的是网页源码,F12是浏览器的开发者工具,在Network-PreserveLog里找POST的请求,可以看Header等
-
Fiddler:抓包
2 反爬虫
2.1 动态加载
有的资源的链接在网页源码里没有(虽然在F12中有,但F12中的不是源码),是通过JavaScript动态加载的,需要通过分析JavaScript代码来得到资源的URL。JavaScript动态加载有内部和外部加载两种,内部的写在HTML页面中,外部的写在单独的JavaScript文件中
2.2 请求头Header中的参数
-
User-Agent:用户代理,用于服务器识别客户的操作系统等等,可以设置成如下等等,
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36可以做一个UserAgent池,防止都是同一个
-
Referer:用于告诉服务器该URL是从哪个URL过来的,网站通过Referer判断访问资源的用户是否来自站内,是则可以访问,不是则不可以
-
Connection:决定当前的事务完成后,是否关闭网络连接,默认是Keep-Alive长连接,多次资源请求复用该连接,可能会导致服务器保持了太多连接而不能再新建连接;一般设置成Close,每次资源请求建立一个新连接,请求完成后立即关闭
-
Cache-Control:缓存控制的开关,max-age=<seconds>设置缓存到多少秒过期,即这些时间内的访问仍得到原来的资源(缓存中的),是为了当请求相同时,不必重复发送资源。然而,当出错或者出现验证码时,会一直得到出错或者验证码页面,No-Cache表示不缓存
2.3 BAN IP
如果同一IP短时间内对一个页面进行了大量的访问,可能会被判断为爬虫程序,然后被封禁IP,解决方案是对爬虫程序设置访问频率(随机sleep)或者使用IP代理池,付费(https://luminati-china.biz/cp/dashboard),免费(https://github.com/jhao104/proxy_pool)
2.4 BAN Cookie
服务器对每一个访问网页的人都Set-Cookie,给其一个Cookie值,当该Cookie访问超过某一个阀值时就BAN掉该Cookie,过一段时间再放出来,当然一般爬虫都是不带Cookie进行访问的,这种主要是针对要登录的网站,网页上的一部分内容是需要用户登录才能查看(如新浪微博),可以禁止Cookie或使用Cookie池。
3 爬虫项目
3.1 商品比价的实时爬取
-
京东:直接Requests即可得到
-
苏宁:价格是从Json中动态加载的,网页源代码中没有,直接Requests得不到,需要根据两个id拼出一个URL去获取URL进而得到价格,其他部分可以直接Requests
-
参考:https://www.pythonf.cn/read/4370
-
在F12开发者工具的Network中搜索任意一个商品的价格,

在Filter(筛选器)中搜索上面得到的xxxx23295,

返回的Json数据有多条,每条对应一个价格,并且页面中各商品价格的存放也没有一点规律,很难分析
-
这时可以点进一个商品,到其商品详情页面,重复上述操作,因为每个详情页商品价格返回肯定是唯一的,并且容易分析出URL的构造方法。如下图,找到了价格,存储在
promotionPrice下,
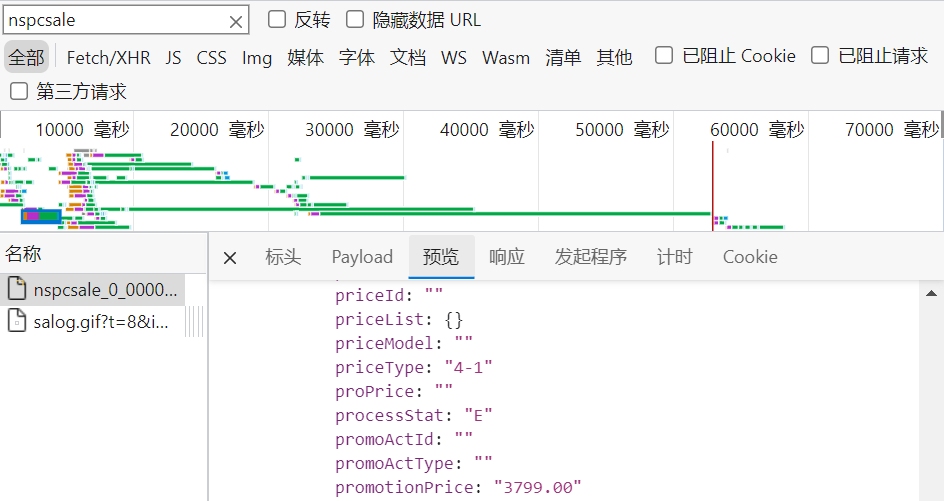
-
接下来是分析URL是如何构造的,原始HTML为,
<div class="price-box"> <span class="def-price" datasku="12313015493|||||0000000000" brand_id="000060021" mdmGroupId="R1901001"> </span>而请求Json的URL为,
http://pas.suning.com/nspcsale_0_000000012313015493_000000012313015493_0000000000_20_021_0210101_500353_1000267_9264_12113_Z001___R9006850_2.86_0___000278188__.html?callback=pcData&_=1558663936729可以看出,URL为格式如下,其中
A为datasku的前半部分,长度为18位,B为datasku的后半部分,长度为10位,这两部分长度不足的要用0在前面补齐http://pas.suning.com/nspcsale_0_A_A_B_20_021_0210101_500353_1000267_9264_12113_Z001___R9006850_2.86_0___000278188__.html?callback=pcData&_=1558663936729
-
-
天猫:直接Requests即可得到
-
淘宝:商品信息都是Javascript加载的,网页源代码中都没有,直接Requests得不到,需要用Selenium,但是用Selenium输入账号密码时,需要滑动框,会被设别,滑动失败,需要扫码登录,而且Selenium较慢
3.2 社交网络的数据获取
如果一直用一个IP爬取,会出现滑动验证框,因此使用了IP代理池,爬取的时候不需要登录,因此不用管Cookie。
-
某个贴吧里的贴子,
页数从0开始,为50的倍数,若将&pn=页数省略,则为第1页https://tieba.baidu.com/f?ie=utf-8&kw=吧名&pn=页数 https://tieba.baidu.com/f?ie=utf-8&kw=钓鱼&pn=50 -
主题贴的URL,
主题贴ID要从上面的贴吧页面中利用正则表达式解析出来,页数从1开始逐个增1,可省略https://tieba.baidu.com/p/主题贴ID?pn=页数 https://tieba.baidu.com/p/7673623118?pn=2 -
楼中楼的URL,楼中楼的内容在主题贴页面中无法直接Requests到,有专门的URL,
楼层ID在主题贴中为pid,页数从1开始逐个增1,不可省略https://tieba.baidu.com/p/comment?tid=主题贴ID&pid=楼层ID&pn=页数 https://tieba.baidu.com/p/comment?tid=7680301876&pid=142703963377&pn=1 -
用户主页
https://tieba.baidu.com/home/main?id=用户ID https://tieba.baidu.com/home/main?id=tb.1.1de4533a.cfgbPJKBVKX-Z78cfPWPEQ?t=1601697130 -
用户回复过的贴子,如果用户隐藏了就找不到了
https://tieba.baidu.com/f/search/res?ie=utf-8&qw=用户昵称