1 HDFS
Hadoop分布式文件系统。HDFS集群有1个NameNode(管理节点,其实还有几个StandBy的用于备份)和多个DataNode(工作节点)。NameNode管理文件系统的命名空间和编辑日志,维护系统文件树,DataNode存储数据。HDFS有数据分块(block),默认128MB,文件被划分为多个128MB的分块,小于128MB的只占实际大小,而不是128MB。数据块过小会导致寻址时间占比过高,任务太多(每个块一个任务),负载过高,任务变慢;数据块过大会导致任务太少,并发度太低,任务变慢。
- 流式数据访问:一次写入,多次读取是最高效的访问模式
- 文件只支持单个写入者,不支持多个写入者
- 写操作总是以”只添加”的方式在文件末尾写数据,不支持在文件任意位置修改
- NameNode将文件系统的元数据存储在内存中,对小文件不友好(小文件太多导致元数据太多,NameNode内存占用增加)
- HDFS是为高数据吞吐量设计的,因此延迟较高,不支持实时查询
1.1 写数据

客户端将文件切分成数据分块,每个块将被存储到3个地方。客户端向NameNode请求写入一个数据块,NameNode返回给客户端3个按距离排序的DataNode的地址,这一组DataNode构成一个管线,客户端向第一个DataNode发送数据(发送时数据块进一步切分为数据包,通常64KB),该DataNode在接受数据的同时也把数据发给下一个DataNode。
一旦该数据块的3个备份都写入完成后,3个DataNode向NameNode报告。剩下的数据块进行同样的操作。
1.2 读数据
客户端向NameNode请求读一个文件,NameNode返回该文件每个数据块的3个DataNode的位置,客户端从最近的DataNode下载数据。
1.3 容错
运行在大量廉价商用机器上,硬件错误是常态,HDFS提供容错机制。
1.3.1 节点故障
如果NameNode挂掉了,整个集群就挂了。DataNode的检测为,DataNode每3秒向NameNode发送一个心跳信号,若NameNode10分钟都没收到某DataNode的信号,就会认定该DataNode挂掉了,即使是发生了网络故障。
1.3.2 网络/通讯故障
每当发送数据时,接收者会回复一个应答信号,如果多次尝试后没有收到应答信号,发送者就会认为接收者发生了网络故障或者挂掉了。
1.3.3 数据损坏
数据在存储时会存储校验和,DataNode会定期向NameNode发送报告,发送数据前,会检测校验和是否正常,然后发送自己还有哪些正常的数据块,NameNode就知道该DataNode是否有损坏的数据。
1.3.4 读写故障的处理
写入数据时,若客户端没有收到某DataNode的应答信号,则跳过该DataNode传入数据;读数据时,如果一个DataNode挂掉了,则会从剩下的其他节点中读取。

NameNode中含有两张表,一张表包含各个数据块的各个备份的位置,另一张表包含各个DataNode中存储了哪些数据块,NameNode会持续地更新这两张表。NameNode会定时扫描数据块的列表,检查数据块有没有被正确地备份(如默认是3个备份),对没有充分备份的数据块,指定一个DataNode进行备份。
1.4 副本布局
集群被分为不同的机架,每个机架上有多个DataNode,如果写入者是集群的成员,那么他就被选为第一副本,否则随机选择;选择一个不同的机架选择两个不同的DataNode存另外两个副本。后续副本选择满足以下条件的DataNode:每个DataNode只存储一份备份,每个机架最多存储两份备份。
1.5 常用命令
关于hadoop fs和hdfs dfs的区别如下图,前者可以指向多种文件系统,当使用HDFS时,两者相同。

HDFS也有也有根目录/,文件都是在根目录下。命令为hdfd dfs -选项,以下主要介绍选项,跟Linux本地文件系统的命令基本相似。
- ls:查看目录下的文件
- cat:查看文件内容
- mkdir:创建目录
- rm:删除文件,-r为递归地删除目录及其目录下的内容
- cp:复制
- mv:移动
上面的命令都是在HDFS文件系统内部进行的操作,下面的put和get是在本地和HDFS之间进行的操作。
-
put:将本地文件系统的文件复制到HDFS,-f为若目标存在则覆盖
hdfs dfs -put -f /opt/hadoop-3.2.1/README.txt /input/README.txt -
copyFromLocal:同put
-
get:将HDFS的文件复制到本地文件系统,
hdfs dfs -get /input/README.txt /opt/hadoop-3.2.1/README.txt -
copyToLocal:同get
-
连接远程的HDFS,本机要装Hadoop,因为要有hdfs的命令(远程机是实际运行的,更要装Hadoop),访问权限在
core-site.xml里配置,默认是都有权限访问的hdfs dfs -选项 hdfs://IP地址:端口/目录 hdfs dfs -ls hdfs://172.16.0.1:9000/input/
2 Yarn

Yarn用于管理集群资源(如内存和CPU等),并向计算框架如MapReduce和Spark提供使用这些资源的API,并隐藏管理资源的细节。
2.1 架构
- Resource Manager:资源管理器,管理集群上的资源
- Node Manager:节点管理器,在每个节点上,管理容器,并向Resource Manager报告
- Container:容器,对资源如内存和CPU的一层抽象,一个Node Manager/节点上可以有多个Container
- Application Master:管理任务

(1)客户端Client提交Yarn应用(Job);
(2)请求RM运行一个Application Master(Spark中为Driver),随后RM在一个NM的Container中启动Application Master;
(3)Application Master将Job解析为一个由若干个Task组成的有向无环图(DAG),并从NameNode获取Task输入数据的存储位置(Block的位置),随后向RM请求计算资源;
(4)RM根据Block的位置,为每个Task分配一个NM List,并返回给Application Master(数据本地化,NM跟Task所需输入数据的DataNode在一个Server上);
(5)按照DAG的划分以及NM List,AM按照并行次序将Task提交给NM;
(6)NM接收Task后,启动Container,运行Task,并向Application Master汇报运行状态和进度;
(7)Application Master向Client反馈Job运行进度和状态,并返回最终结果

Active的ResourceManager和NameNode不能在同一个Server上,这非常危险,一个Server挂了,两个Master就都挂了。NodeManager和DataNode在同一个Server上,减少通讯开销。
Yarn应用可以在运行中的任意时刻提出资源申请。可以在最开始提出所有的请求,如Spark在集群上启动固定数量的Executor;也可以为了满足不断变化的应用需求,在需要更多资源的时候提出请求,如MapReduce在最开始申请map任务容器,后期申请reduce任务容器。
2.2 调度
在一个集群上,有多个应用请求资源时,通过一定的调度策略为应用分配资源,主要有以下三种:
-
FIFO调度器(First Input First Output Scheduler):为先提交的应用分配资源,第一个应用被满足后再为下一个应用分配。优点是简单,缺点是大的应用会占用集群的资源,导致后面的小应用无法运行。

-
容量调度器(Capacity Scheduler):预留一个专门的队列,保证小作业(下图中的作业2)一提交就可以启动,小作业更早的完成了,不过大作业会比FIFO中完成的要晚。而且在小作业提交之前和完成之后,该队列是空的,会降低集群的利用率。

-
公平调度器(Fair Scheduler):不需要预留资源,会在所有运行的作业中动态地平衡资源。如下图,大作业(作业1)提交时,它是唯一的作业,获得全部的资源;小作业提交时,大作业和小作业会各自占用一半的资源。这种情况下大作业比容量调度中完成要晚,不过集群的利用率较高,也能保证小作业及时完成。

用户队列间的公平调度如下图所示,两个用户A和B分别拥有自己的队列,在A启动作业1一段时间后,B启动作业2,这样两者各获得一半的资源,之后B再启动作业3,这样作业2和3将各自共享原来的一半,即1/4的资源。

2.3 优势
在MapReduce 1中,JobTracker 同时负责作业调度和任务进度监控。在Yarn中,Resource Manager负责作业调度,Application Master负责任务进度监控。

- 扩展性:在MapReduce 1中,由于JobTracker要同时管理作业和任务,当节点很多,任务数很大时,MapReduce 1会遇到可扩展性瓶颈;而Yarn将两者分离,克服了这个局限性
- 利用率:在MapReduce 1中,每个TaskTracker都有多个槽(slot),在配置时就被划分为map slot和reduce slot,两者不通用,会导致有空闲的map slot,而reduce任务没有空闲的reduce slot来执行;而Yarn中,每个Node Manager管理很多个Container,不存在这个问题
3 MapReduce
3.1 架构
一个MapReduce应用有多个作业(Job),Shuffle将Job划分为了Map和Reduce两个阶段(Stage),每个Stage都有多个Map或Reduce任务(Task),每个任务对应于一个分片/分区的计算,这些任务运行在集群的节点上,每个节点上可以有多个Container,每个Container执行一个Map任务。Map任务和Reduce任务的输入输出都是一些键值对。
3.2 工作流程
一个MapReduce的处理流程如下(气象数据处理):

3.2.1 Map
Hadoop将MapReduce的输入数据划分成等长的数据块,成为输入分片(Input Split),Map一般从HDFS中读数据,因此分片大小一般为HDFS数据块(block)的大小,即128MB。Input Split是一组Key-Value键值对。Hadoop为每个分片构建一个Map任务(Map任务的数量为输入分片Split的数量),若在存有输入数据的节点上运行Map任务,可以获得最佳性能(无需使用集群带宽),这就是数据本地化,若HDFS数据块所在节点在运行其他Map任务,则需要调度该机架的一个节点上的一个空闲的Map槽来运行。
Map任务的输出写入本地磁盘,而非HDFS,因为该输出是中间结果,Reduce任务的输出将写入HDFS(多个副本)。Reduce任务不具备数据本地化的优势,因为Reduce的输入通常来自所有的Map任务的输出。

3.2.2 Reduce
Reduce任务的数量可以指定,默认为1。若有多个Reduce任务,每个Map任务(通常Map任务数大于Reduce任务数)就会对输出进行分区(Partition),每个Reduce任务一个Partition。每个分区有很多键,相同的键都在同一分区中,通常通过哈希函数HashPartitioner来决定哪个键去哪个分区(键相同的哈希取模后也相同,键不同的哈希取模后也可能相同,达到分组的目的)。每个Reduce任务输出一个文件。
3.2.3 Shuffle
Map任务和Reduce任务之间的数据流称为混洗(Shuffle),Shuffle是由Map和Reduce之间的强依赖关系导致的(Map任务的输出决定着多个Reduce任务的输入,跟Spark中的宽依赖相同),Shuffle是虚拟阶段,分为Map端Shuffle和Reduce端Shuffle。Shuffle的过程非常消耗资源,应尽量减少或避免。Shuffle包括Partition(分区)、Sort(排序)、Spill(溢写)、Merge(合并)和Fetch(抓取)等工作。

- Map端:Map Task将其输出写入环形内存缓冲区Buffer(默认100M)中,同时进行Partition和Sort,当Buffer中的数据量达到阈值(默认80M)时,将缓冲区内的数据溢写(Spill)到磁盘中的一个临时文件中(文件中的数据是已经先分区后排序好的),Map Task结束前,将多个临时文件合并(Merge)为一个Map输出文件(文件中的数据也是已经先分区后排序好的)
- Reduce端:Reduce任务从多个Map输出文件中抓取(Fetch)属于自己的分区数据,对抓取到的分区数据做归并排序,生成一个Reduce输入文件(文件内数据按key排序)。如果内存缓冲区够大,就直接在内存中完成归并排序,然后落盘;如果内存缓冲区不够,先将分区数据写到相应的文件中,再通过归并排序合并为一个大文件。
输入输出的格式为Key-Value的一个原因是要靠key来分区和排序。
4 Hive
Hive是Hadoop的数据仓库。HDFS上的数据其实都是文件,没有良好的组织形式,Hive将这些数据规整起来,让用户可以用结构化数据库的角度去使用这些数据,顶层使用Hive SQL操作,底层被翻译成MapReduce去查询计算数据(方便不懂MapReduce的SQL人员使用)。Hive适合用来对一段时间内的数据进行分析查询如日志分析,不应该用来进行实时的查询,因为它需要很长时间才可以返回结果。
目前最新版本的执行引擎已由Tez替代了MapReduce,引擎也可以用Spark,结构上Hive On Spark(我们一般用的是Hive On MapReduce)和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。
4.1 架构

- Driver:将编写的HiveQL(类SQL)语句解析、编译、优化,生成执行计划,然后调用底层的MapReduce框架
- HiveServer2:让Hive以提供Thrift服务的服务器形式运行,使客户端能通过JDBC/ODBC连接
- Metastore:存放元数据,如表名、表所属的数据库、表的拥有者、分区字段等等。存储在关系型数据库中,默认为本地磁盘的内嵌的Derby数据库,同一个目录下同时只能有一个Hive客户端能使用数据库;也可以存储在本地或远程的MySQL数据库中。在配置文件
hive-site.xml中设置,若hive.metastore.uris未设置,则为本地,否则为远程 - Beeline:可以在本地以内嵌的方式运行,相当于原来的CLI(Command and Line Interface,命令行接口),也可以基于JDBC远程连接HiveServer2
4.2 数据模型

一个数据库有多个表Table,每个表有多个分区Partition,每个分区可以有多个分桶Bucket,也可以直接对表进行分桶,但一般是对分区进行分桶。系统会为每个数据库创建一个目录,目录名为数据库名.db。
4.2.1 表Table
元数据存放在Metastore中,而表数据存在HDFS中,分为内部表(托管表)和外部表。默认创建的是内部表。外部表相对来说更加安全些(能够防止误删除),数据组织也更加灵活,方便共享源数据。
- 内部表:存储位置由
hive-site.xml的hive.metastore.warehouse.dir指定,默认为HDFS下的/user/hive/warehouse目录,会将源数据移动到该目录下,删除的时候表数据会被一起删除 - 外部表:数据还存储在原来的位置,删除的时候不删除表数据
而元数据都会删除。一个内部表对应于数据库目录下的一个子目录,目录名为表名。
4.2.2 分区Partition
将表按照一个或多个字段划分为多个部分,这些字段称为分区键,减少不必要的全表扫描,缩小查询范围,提升查询效率。一个分区对应于表目录下的一个子目录,目录名为分区键。
- 单值分区:根据分区键的值,一种值一个部分,将表分为多个部分,分区键不允许出现在表结构中,如一个表包含name、city、province、state四个字段,使用state作为分区键

- 范围分区:根据分区键的值的范围,一部分值一个部分,将表分为多个部分,分区键可以出现在表结构中
分区键的选择:分区键通常高频出现在Select … Where条件查询中;为了避免产生过多的子目录和小文件,只对离散字段进行分区,如日期、地域、民族等,而不选择连续值的分区;提前对分区数量进行预估,尽量避免数据倾斜。
4.2.3 分桶Bucket
将字段(使用的字段称为分桶键)的哈希值对桶数N进行取模,将分区数据随机分到N个桶中,这样,字段值相同的行在同一个桶中。不是只放分桶键,而是整行,因为并不是对所有字段都进行分桶。

这样能够提高Join操作的效率,如果两个表要进行Join操作,并且这两个表都进行了分桶操作且桶数N相同(或成倍数),那么这两个表中字段值相同的行就在编号相同的桶中,对于Join操作,要找相同的字段值,只需在两个表相同编号的桶中寻找即可。分桶键必须出现在表结构中。在表或分区目录下,每个桶存储为一个文件。
4.3 Hive SQL
-
数据类型
- boolean
- int
- float
- double
- char
- varchar
- date
以下是Hive特有的
- string:无上限可变长度字符串
- array:数组,一组有序字段,所有字段的数据类型必须相同,array(1,2)
- map:字典,一组无序的键值对,键的类型必须是原子类型,值的类型任意,同一个map的键的类型必须相同,值的类型也必须相同,map(‘a’:1,’b’:2)
- struct:一组命名的字段,字段的数据类型可以不同,类似于C++的struct和Java的类,struct(‘a’,1,1.0)
-
创建表
create table 表名 (字段名1 类型,字段名2 类型,...); create table records (year string,temperature int,quality int);row format声明源数据的模式,如下句代表源数据的每一行以制表符做分隔符
create table records (year string,temperature int,quality int) row format delimited fields terminated by '\t';external创建外部表,需要用location指定其存储位置,默认为内部表
create table records (year string,temperature int,quality int) location '/user/tom/abc';like复制表结构,不复制数据
create table 表名 like 已有表名;as select既复制表结构,又复制数据
create table 表名 as select <select语句>;partition by创建单值分区,分区键不允许出现在表结构中
create table records (year string,temperature int,quality int) partition by (country string);clustered by创建分桶,分区键必须出现在表结构中
create table users (id int,name string) clustered by (id) into 4 buckets; -
装入数据
load,overwrite代表覆盖表内原有数据
load data inpath '路径' [overwrite] into table 表名; load data inpath 'input/xxx.txt' into table records;当把数据加载到已分区的表中,要显示指定分区值
load data inpath 'input/xxx.txt' into table records partition(country='CN');数据源和目标文件要在同一个文件系统中,即数据源要在HDFS中,相当于做了移动操作。若数据源来自本地,需使用
local。加载操作就是文件系统中的文件移动或重命名,因此执行速度很快,Hive并不检查目录中的文件是否符合表所声明的模式,如果有数据和模式不匹配,只有查询时才会知道(读时模式,适合处理大规模数据)load data local inpath 'input/xxx.txt' into table records;insert,前者为覆盖,后者为插入
insert overwrite table 表名 <select语句>; insert into table 表名 <select语句>;- 创建表中的
create as select是创建一个新表
-
查询数据,接下来就可以跟MySQL一样查询操作据了
select * from records;主要介绍与MySQL不一样的
-
排序
order by全局排序,将所有数据交给一个Reduce任务计算,实现查询结果的全局排序,如果数据量很大,只有一个Reduce会耗费大量时间
select * from records order by year;sort by局部排序,启动多个Reduce任务时,每个任务的输出文件内有序
select * from records sort by year;distribute by聚合,将列值相同的数据发送到同一个Reduce任务中,如下面语句代表所有具有相同年份的行都在同一个Reduce分区中,通常与sort by配合使用,且先distribute后sort,下面的语句相当于在每个年份中按温度排序
select * from records distribute by year sort by temperature;cluster by,如果distribute by和sort by的列完全相同,可以缩写为cluster by
select * from records cluster by year; -
复杂类型,如map,其表结构就可以是如下所示,
+----------+----------------------------------+--+ | name | score | +----------+----------------------------------+--+ | Tom | {Chinese:80,Math:60,English:90} | | Jerry | {Chinese:90,Math:80,English:70} | | Grey | {Chinese:88,Math:90,English:96} | | John | {Chinese:99,Math:65,English:60} | +----------+----------------------------------+--+ -
将行转为列
- explode
select explode(score) as (class,class_score) from student_score; +---------+-------------+--+ | class | class_score | +---------+-------------+--+ | Chinese | 80 | | Math | 60 | | English | 90 | | Chinese | 90 | | Math | 80 | | English | 70 | | Chinese | 88 | | Math | 90 | | ... | ... | +---------+-------------+--+- explode(函数),例如有一个字段
name为string类型,可以进行切分
hello word hello hadoop spark zookeeper hive hbase select explode(split(name,' ')) as word from xxx_;- lateral view,关联其他字段
select * from student_score lateral view explode(score) new_table as class,class_score; +--------+---------+-------------+--+ | name | class | class_score | +--------+---------+-------------+--+ | Tom | Chinese | 80 | | Tom | Math | 60 | | Tom | English | 90 | | Jerry | Chinese | 90 | | Jerry | Math | 80 | | Jerry | English | 70 | | Grey | Chinese | 88 | | Grey | Math | 90 | | ... | ... | ... | +--------+---------+-------------+--+ -
Beeline,连接远程的Hive,连接后就相当于在本地使用
hive命令进入命令行>beeline -u "jdbc:hive2://IP地址:10000/数据库名" -n 用户名 -p 密码 -
查看执行计划,某个查询使用多少MapReduce作业
explain 语句; -
连接
join内连接,MapReduce端的过程如下,根据输入文件的大小(128MB切),每个Map处理两个表的一部分数据,Map的输出Key为on后面的条件字段,即两个表的uid;输出Value包括属于哪个表的tag和select的内容,即1或2,以及name和orderid。Shuffle将Key相同的数据移到同一个Reduce分区。每个分区的都是满足连接条件的数据,Reduce就可以根据tag完成连接
select u.name, o.orderid from order o join user u on o.uid = u.uid;
left join左外连接right join右外连接full join全外连接left semi join半连接,类似于in子查询,select里只能有左表的字段,对于左表中的一条记录,在右表中一旦找到匹配记录就停止扫描
select * from users where users.uid in (select uid from orders); select * from users left semi join orders on (users.uid=orders.uid);-
map join,join操作需要非常消耗资源的Shuffle操作,map join将连接在Map端完成,条件是连接的表中必须有一个小表足以放到每个Map任务所在机器的内存中,每个Map都会拿到小表的一个副本,然后扫描大表中的一部分数据,与各自的小表副本完成连接操作,这样就可以在Map端完成连接操作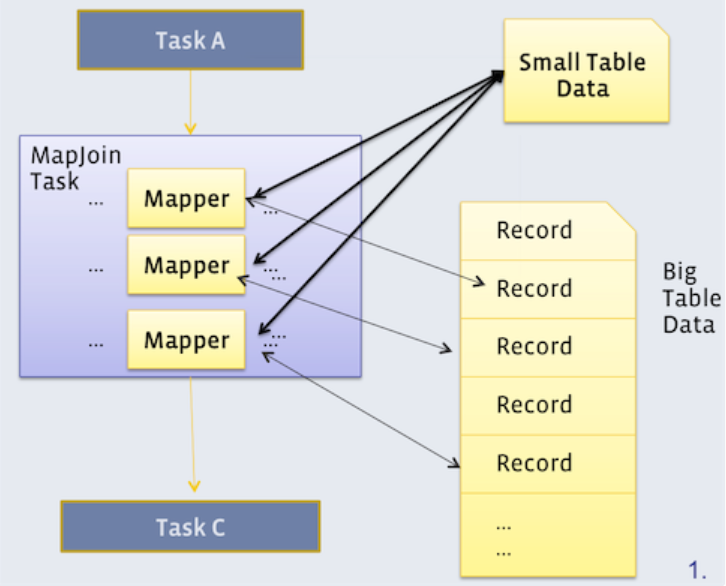
-
bucket map join,当两个表都不是小表时,需要用这种join,先对两个表进行分桶,每个Map处理一个表的一个或多个桶,每个桶只需要找另一个表中编号相同的桶进行连接即可 -
sort merge bucket map join,若每个桶内是已经排好序的,则连接的时候可以直接归并排序
-
一个完整的MapReuce执行过程
对如下语句,Hive将翻译成如下图的MapReduce执行流程,
select city,count(order_id) from orders_table where day='201901010' and cat_name='iphone7' group by city;

输入文件为day=201901010的分区文件,根据文件大小切分输入分片(128MB切一次),对每个分片启动一个Map任务,输入的Key-Value为每行数据的偏移量和该行数据,输出的Key为city,Value为1(因为select的是这两部分),Combine阶段将Key相同键值对合并(这一阶段是可选的),Shuffle阶段将Key相同的移到一个分区,每个分区执行一个Reduce任务,将Key相同的合并,最后输出。因为是统计次数的,所以这个过程其实跟WordCount很相似。
4.4 调优
当数据倾斜时,会使性能下降,如key的分布不均匀,使得大量的数据集中到某一个Reduce任务上,需要进行调优。在进行Join操作时,如果有大量的空值,由于NULL的哈希值相同,所以他们会分配到同一个Reduce任务上,造成数据倾斜,解决方案是让NULL不参与连接,或者给NULL随机赋值
参考:
5 ZooKeeper
5.1 理论
5.1 CAP理论
网络分区:一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中。
当某个数据项只在一个节点中保存,那么网络分区出现后,和这个节点不连通的部分就访问不到这个数据了,这时网络分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里,容忍性就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的,要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
总的来说就是,数据存储在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
-
C:Consistency,一致性,同一时刻,数据在不同节点的多个副本是否具有完全相同的值
-
A:Availability,可用性,对于每一次请求,系统是否都能在有限的时间内做出响应
-
P:Partition Tolerance,分区容忍性,当发生网络分区时,分离的系统仍能正常运行
CAP理论指,分布式系统在同一时间段内,最多只能满足CAP中的两项,且P是必须满足的,若不满足,发生分区故障时,分布式系统就不能用了。
-
CP:当发生分区故障时,若要保证C一致性,则不能满足A,客户端的请求会卡死或超时,因为只要请求得到响应,两边的数据就不一致(分区故障导致不是连同的)。
-
AP:反之,当发生分区故障时,若要保证A可用性(即分裂的两边都能读写),则数据会不一致,不满足C。
5.2 BASE理论
- BA:Basically Availability,基本可用性,当系统发生故障时,在确保核心功能和指标有效的提前下,允许损失部分可用性(包括响应时间上的损失、非核心功能上的损失等)
- S:Soft State,软状态,允许数据存在中间状态(暂时未更新),且该状态不会影响整体可用性;允许不同节点上的数据副本的同步过程存在一定延时
- EC:Eventually Consistency,最终一致性,分布在不同节点上的数据副本,在经过一定时间的同步后,最终达到一致状态
分布式系统在满足分区容错性P的同时,允许数据软状态S(容忍部分数据的暂时不一致)的存在,并实现基本可用性BA和最终一致性EC,在CAP的基础上,A→BA、C→EC。
5.2 原理
5.2.1 架构

- Leader:接收Follower和Observer转发的写请求;事务的发起和决议
- Follower: 客户端读请求可以直接处理;写请求需要转发给Leader;参与Leader发起的事务处理和Leader的选举;同步Leader状态
- Observer:客户端读请求可以直接处理;写请求需要转发给Leader;不参与Leader发起的事务处理和Leader的选举;同步Leader状态
过半策略:事务处理和Leader选举采用过半策略,若Leader+Follwer的数量为m,则Quorum=m/2+1,只有投票数≥Quorum,事务和选举才判定成功。Leader+Follwer的数量最好是奇数(2n+1),在不影响事务处理的前提下,最多可容忍n台宕机(例如:对于节点数为5和6的两个集群,二者都最多容忍2台宕机,所以容灾能力相同;前者的 Quorum数为3,后者为4,前者更小,事务处理和选举的效率更高)。进行写操作时,有的节点响应的快,有的慢,等都写完响应时间太久,因此才有过半策略。
引入Observer的原因:由于Observer只对读请求进行处理,而对写请求只作转发处理,且无需参与事务处理,因此能够提高集群的读取能力,跨中心部署Observer,为本地读请求提供快速响应。Observer宕机也不影响集群的可用性,能提高集群的大规模访问的承载能力。不过,由于要转发写请求和同步Leader状态,跨中心部署并不能彻底消除网络延迟。如果仅增加Follower,虽然提高了读能力,但由于要参与事务处理,会降低写能力和集群承载能力。
最终一致性:保证数据在各节点的副本(Leader、Follower、Observer)最终能够达到一致状态,这是ZooKeeper最重要的功能。
5.2.2 ZAB协议
ZooKeeper Atomic Broadcast,ZooKeeper原子广播协议,基于该协议,ZooKeeper实现了集群各节点副本数据的最终一致性。
- 数据写入

(1)Follwer接收客户端写请求,并将其转发给Leader;
(2)Leader接收写请求,为其分配一个全局唯一的事务ID,Zxid(64位/单调递增);
(3)Leader生成一个形如(Zxid, data)的事务提案Proposal,广播给各Follower;
(4)Follower接收Proposal后,先以事务日志的形式落盘,再向Leader发送ack;
(5)当Leader接收到超过半数的ack之后(包括Leader自己),会向Follower发送commit命令,要求提交事务,同时自己在本地commit;
(6)Follower收到commit命令后提交事务,同时向客户端反馈结果。
- 数据读取
客户端直接从Follower或Observer读取数据,由于有的Follower可能没有及时commit,数据不是最新的,如果要确保读到最新数据,应该先调用sync()进行强制同步。
5.2.3 Leader选举
选票的数据结构为(sid, zxid),sid为服务器id,zxid为当前服务器的最大事务id。选票的比较规则为:zxid大的胜出,若相等,则sid大的胜出。因此,在所有参选的Follower中,新Leader拥有zxid最大的已提交事务。
- 启动期间的Leader选举

(1)ZK1启动并投票(1,0)给自己,发现未过半数,选不出Leader;
(2)ZK2启动并投票(2,0)给自己,ZK1仍投票(1,0)给自己,统计第1轮投票,ZK1和ZK2均未超过半数,选不出Leader,同时ZK1更新自己的选票为(2,0);
(3)发起第2轮投票,ZK1投(2,0),ZK2投(2,0),统计第2轮投票,ZK2两票,超过半数,ZK2当选新的Leader;
(4)ZK3启动,发现已有Leader,不再选举。
启动期间的zxid均为0。
- 运行期间的Leader选举

运行期间的zxid不再为0。
5.2.4 Znode
Znode是ZooKeeper的最小数据单元,节点有数据存储功能,大小不能超过1M,节点中的数据应尽可能小,数据过大会导致ZK性能明显下降,如果要存储较大的数据,则将数据存到数据库中,而存储地址放到Znode中。

Znode Tree是Znode通过挂载子节点而形成的一个树状层次化命名空间,绝对路径作为节点名称,用于唯一标识节点,根节点为“/”,非根节点为不能以“/”结尾。
会话(Session):客户端为实现Znode读写操作而与ZooKeeper服务器建立的TCP长连接,客户端会通过心跳检测(Ping)或发送读写请求来激活和保持会话, 但服务器要是一直未收到客户端消息,就会判定超时并关闭会话。
- 持久节点:节点默认类型,生命周期不依赖于客户端会话,只有客户端执行删除操作时,节点才会消失;可以拥有子节点,也可以是叶节点
- 临时节点:生命周期依赖于客户端会话,当会话结束时,节点会自动删除;不能拥有子节点,只能是叶节点
- 顺序节点:带顺序编号的持久或临时节点,创建顺序节点时,在路径后面会自动添加一个10位的节点编号(计数器),该编号在同一父节点下是唯一的
Znode版本是形如0,1,2,…,N的单调递增数字,不是形如v1.2.1的软件版本。数据版本dataVersion:当对Znode中的数据进行更新操作时,dataVersion自增1。利用版本能够确保分布式事务操作的原子性。
- 悲观锁:事务A执行期间,数据全程加锁,其他事务只能等待;适用于数据更新并发度较高的场景
- 乐观锁:事务A提交更新请求前,先检查数据是否被其他事务修改过(通过比较版本进行写入校验), 如修改过,则相关事务必须回滚;适用于数据更新并发度不高的场景,如下图:

5.2.5 Watcher机制

(1)客户端向ZooKeeper集群的某个Znode注册一个Watcher监听器;
(2)客户端把Watcher对象存储到本地的WatchManager中;
(3)当服务端的指定事件触发了Watcher监听器,会向客户端发送事件通知;
(4)客户端根据通知状态和事件类型回调WatchManager中的Watcher对象, 执行相应的业务逻辑(类似QT中的信号槽)。
Watcher是一次性的,一旦触发就会被删除,再次使用时需重新注册。
5.3 应用
5.3.1 配置管理
集群中所有节点的配置信息需保持一致,配置信息修改后,应快速同步到其他节点上。将配置信息写入Znode,各节点监听Znode,一旦Znode的数据被修改,将通知各节点进行更新。

5.3.2 集群管理
- 节点上下线动态监测
实时掌握分布式系统中各节点的状态是集群管理的前提和基础。将节点的状态信息写入Znode,利用Watcher监听Znode,以获取节点的实时状态变化。新节点启动后,先在ZooKeeper中创建临时顺序Znode,这时会触发父节点上的监听器,并通知集群管理节点Master有新节点上线;节点发生故障,失去与ZooKeeper的心跳连接,它创建的临时顺序Znode被自动删除(客户端会通过心跳机制保持会话,若服务端一直未收到客户端的消息,就会判定超时并关闭会话,而临时节点在会话结束后会自动删除),这时会触发父节点上的监听器,并通知Master节点下线。
- Master选举
如果Master节点宕机,失去与ZooKeeper的心跳连接,那么它创建的临时Znode被自动删除,这时会触发该节点的Watcher,并通知所有Standby节点去竞争创建临时Znode,成功创建临时Znode的Standby节点成为新的Master,其他Standby节点在该Znode上注册监听器,等待下一次选举。
5.3.3 统一命名
- 统一命名服务
统一命名服务跟域名类似,都是为某一部分资源取一个名字,别人通过这个名字就可以拿到对应的资源。按照Znode树状层次结构组织服务名称,将服务的地址、目录和提供者等信息存入Znode,通过服务名称来获取相关信息。

- 全局唯一ID
利用Znode顺序节点(父节点下唯一),可以实现ID生成器。
5.3.4 分布式锁
- 方式一
多个客户端同时在ZK上竞争创建临时节点“/Lock”,创建成功的客户端获得锁,并执行事务;其他客户端注册Watcher监听器,监听Lock节点;事务完成后,获得锁的客户端会删除Lock节点,释放锁,同时触发Watcher,通知其他客户端;其他客户端再次竞争创建Lock节点。缺点是:产生羊群效应,即当锁被释放后,如果抢占锁资源的竞争客户端太多,势必会影响性能。

- 方式二
客户端在持久节点“/Lock”下创建临时顺序子节点,第一个客户端创建的子节点为“/Lock/Lock0”,第二个为“/Lock/Lock-1”,以此类推;客户端获取Lock节点的子节点列表,判断其创建的子节点的序号是否最小,如果是则获得锁,否则就监听序号排在其前一位的子节点;锁释放后,对应的子节点被删除,该节点序号后一位的子节点得到通知,重复上一步直至获得锁。

6 HBase
HBase是建立在HDFS上的分布式数据库,HBase不是关系型数据库(RDBMS)。本质是Key-Value数据库,根据Key值就能直接得到Value。支持超大规模数据存储;实时随机读写;高并发点查;线性扩展;高可用;数据强一致性。
6.1 对比
6.1.1 与HDFS
HDFS是一个文件系统(分布式的,我们本地的也是文件系统);HBase是基于HDFS这个文件系统的数据库(同样也是分布式的)。
6.1.2 与MySQL
MySQL是单机的数据库,能存储的数据量小;HBase的可伸缩性强,易于横向扩展(通过廉价的商用服务器来扩展节点)。
6.1.3 与Hive
Hive主要解决数据处理和计算分析问题,底层使用MapReduce来计算;Hbase主要解决实时数据查询问题,两者一般是配合使用(相当于数据仓库和数据库的关系)。在大数据架构中,Hive和HBase是协作关系,数据流一般如下:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- Hive清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase;
- 数据应用(如MapReduce等)从HBase查询数据。
6.2 数据模型

HBase以表的形式存储数据,表由行和列组成。
- 列被划分为多个列族(column family),列族中有多个列,列由列族+列标识符组合而成,如列info:format和列info:geo都是列族info的成员,列contents:image是列族contents的成员。列族必须作为表模式定义的一部分预先给出,一个列族可以任意添加列。
- 每一行都有一个行键(row key)
- 每个单元格都有一个版本,在添加、修改会删除时会记录一个时间戳,当作版本(上图中图片有多张)。
HBase本质是Key-Value数据库,Key由行键、列族、列标识符和时间戳组成,Value就是实际的值。这是四维的,可以转换成由行键和列组成的二维的(跟SQL一样),时间戳取最新的。
6.3 架构
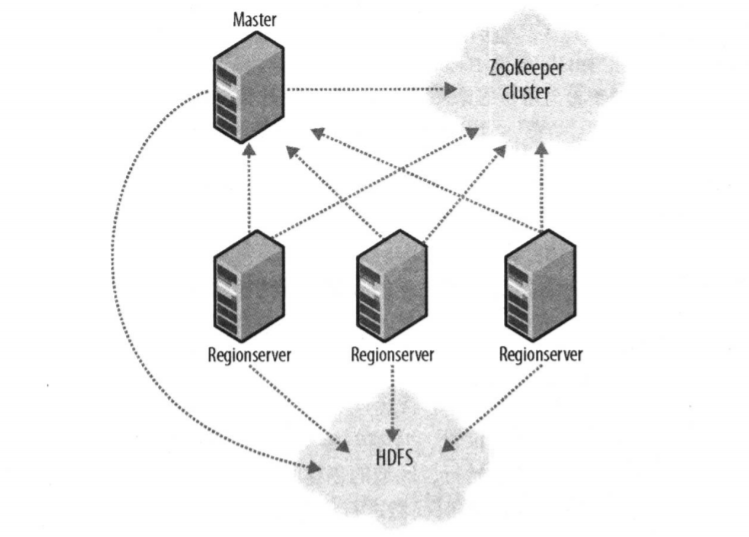
HBase由一个Master节点协调管理多个RegionServer节点,RegionServer与底层的HDFS交互,Master负责Region的分配和RegionServer的负载均衡,而客户端访问数据的过程Master并不参与,因此Master的负载很低。ZooKeeper实现Master的高可用(主备切换);监控RegionServer的上下线信息,并通知Master;存储-ROOT-表,-ROOT-表存的是.META.表的地址。.META.表存储在RegionServer中,存储每个数据表的各个Regin所在的RegionServer信息。
表中的所有行都按照row key的字典序排列,表在行的方向上划分为多个区域(Region)。每个表一开始只有一个Region,随着数据不断插入,Region不断变大,当超过阈值之后,就会等分为两个新的Region。每个Region由一个或多个Store组成,每个Store储存一个列族(列式存储)。数据是按key排序存储的(行键-列族-列标识符-时间戳),其实存储的顺序还是一列一列的。
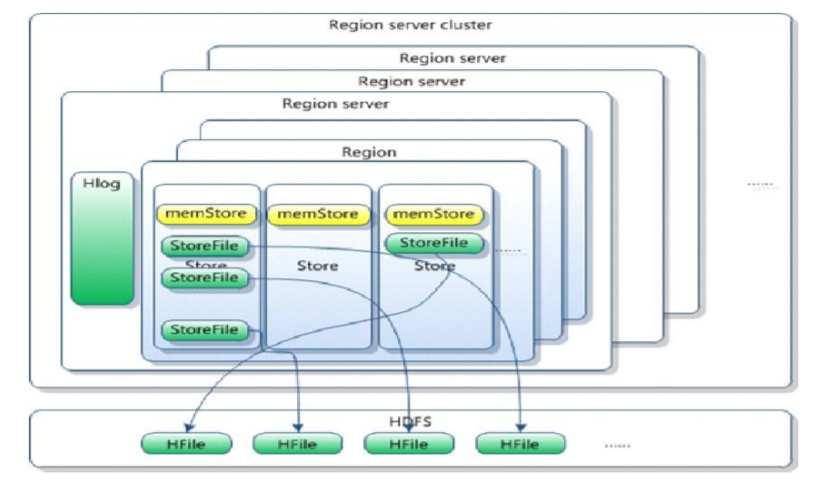
Store由内存中的MemStore和磁盘中的若干StoreFile(底层是存储在HDFS上的HFile,Hadoop二进制文件)组成,MemStore是Store的内存缓冲区,写数据先写MemStore,写满后会溢写到磁盘,生成StoreFile。
- 写操作
(1)客户端向ZooKeeper读取-ROOT-表,并缓存在Cache中,得到了.META.表的地址;
(2)客户端根据该地址读取.META.表,得到目标Region所在的RegionServer的信息;
(3)Client向RegionServer发出写请求;
(4)RegionServer先将操作和数据写入HLog(RegionServer意外宕机时的数据恢复),再将数据写入MemStore;
(5)当MemStore的数据超过阈值时,溢写磁盘生成StoreFile文件;
(6)当StoreFile的数量超过阈值时,将若干小StoreFile合并为一个大StoreFile(为了减少StoreFile数量,提升数据读取效率);
(7)当Region中最大的Store的大小超过阈值时,Region分裂成两个子Region(为了数据访问的负载均衡)。
- 读操作
(1)前3步同写操作,发出读请求;
(2)RegionServer按照MemStore(内存,刚写入还未落盘的数据)→BlockCache(内存,RegionServer会将上一次查找的Block块缓存到BlockCache中,以便后续同一请求或者邻近数据的读取请求,可以直接从内存中获得,采用LRU最近最少使用淘汰策略)→StoreFile(磁盘)的顺序查找;
(3)先将本次查找的Block块缓存在BlockCache中,再返回结果。
- 删除操作
打上删除标记,但不做物理删除,读数据时会忽略。StoreFile小文件合并时才会物理删除。
6.4 数据入库
批量加载数据到HBase集群有多种方式,比如使用HBase API、使用Sqoop工具、使用MapReduce批量导入等。当数据量很大时,这些方式的效率都比较低。BulkLoad能够完成大规模数据的快速入库,由于数据以HFile的形式存储于HDFS,所以可以绕过HBase API,使用MapReduce直接生成HFile格式的数据文件,然后将HFile数据文件移动到相应的Region上去。
7 Spark
7.1 数据模型RDD
Spark的计算基于RDD(弹性分布式数据集),RDD由多个Partition(分区)组成,分区分布在集群中的不同节点中。

7.1.1 RDD操作
RDD有两种操作,转换(Transformation)和动作(Action)。
-
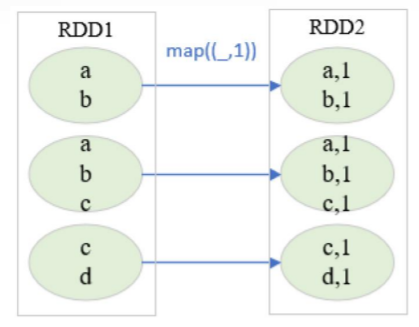
转换,map、filter、flatmap、union、distinct、sortbykey等

- 将输入构造成一个新RDD
- 通过已有RDD产生新RDD
-
动作,first、count、collect、foreach、saveAsTextFile等
- 将RDD保存落盘
- 通过RDD计算得到结果,如求和、求平均值等等
RDD是惰性执行的,转换操作不触发计算,只有到动作操作才触发计算。惰性执行的意思就是等到绝对需要时才执行计算,当用户表达一些对数据的操作时,不是立即修改数据,而是建立一个作用到原始数据的转换计划;Spark首先会将这个计划编译为可以在集群中高效运行的流水线式的物理执行计划,然后等待,直到最后时刻才开始执行代码;这会带来很多好处,因为Spark可以优化整个从输入端到输出端的数据流。一个很好的例子就是DataFrame的谓词下推,假设我们构建一个含有多个转换操作的Spark作业, 并在最后指定了一个过滤操作,假设这个过滤操作只需要数据源(输入数据)中的某一行数据,则最有效的方法是在最开始仅访问我们需要的单个记录,.first()也是一样的,Spark会通过自动下推这个过滤操作来优化整个物理执行计划。
7.1.2 RDD依赖
转换操作有两种依赖,窄依赖(Narrow Dependency)和宽依赖(Wide/Shuffle Dependency)。
- 窄依赖:每个父RDD分区只能为一个子RDD分区供数,全部在内存中执行,如map、filter、union

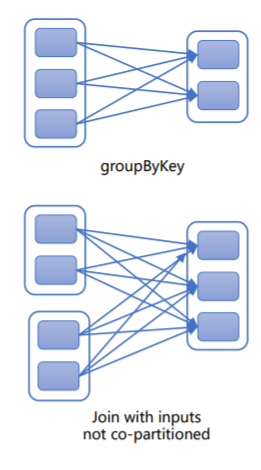
- 宽依赖(Shuffle):每个父RDD分区为所有子RDD分区供数,结果写入磁盘,如groupByKey、reduceByKey、sortByKey,相对于窄依赖,宽依赖付出的代价要高很多,应尽量避免使用。Shuffle操作默认会输出200个分区
7.2 执行过程
- Driver:管理一个Spark应用程序
- Executor:执行Driver分配的任务,一个节点可以启动多个Executor,相当于Yarn中的Container
一个应用程序(Application)有多个Spark作业(Job),一个动作触发一个Job,每个Job根据Shuffle划分阶段(Stage,MapReduce也相当于通过Shuffle划分为了Map和Reduce两个Stage),其中Shuffle操作会将数据持久化(如写入磁盘),每个Stage有多个任务(Task),每个任务对应一个数据分区的一组转换操作,每个Executor上可以运行多个Task。并行体现在数据分为多个分区,这些分区对应的Task可以并行计算。
其中,每个Driver创建一个SparkContext,SparkContext负责加载配置信息,初始化运行环境,创建DAGScheduler和TaskScheduler。DAGScheduler根据任务的依赖关系建立DAG(有向无环图),根据依赖关系是否为Shuffle,将DAG划为不同的Stage。TaskScheduler负载任务调度,重新提交失败的Task,以及为执行速度慢的Task启动备用Task。
Job执行过程如下:

(1)生成逻辑计划

(2)根据逻辑计划生成物理计划

(3)进行任务调度和执行

生成逻辑计划、物理计划和任务调度在Driver中进行,任务执行在Executor中进行。
7.3 运行模式
7.3.1 Local模式
单机运行,通常用于测试,Spark程序以多线程方式直接运行在本地。
7.3.2 Standalone模式

- Master(集群驱动器):统一管理集群资源,相当于Yarn中的ResoucreManager
- Worker(集群执行器):集群的工作节点,负载本地计算,相当于Yarn中的NodeManager
此模式中Spark集群独立运行,不依赖于第三方资源管理系统。
7.3.3 Yarn模式
- Yarn-Client模式:适用于交互和调试,Driver放在客户端机器上

- Yarn-Cluster模式:适用于生产环境,Driver放在NodeManager上

Spark On Yarn-Cluster与MapReduce的执行过程一样。
- Master-ResourceManager
- Worker-NodeManager
- Driver-Application Master
- Executor-Container
7.4 优势
- 不同于MapReduce将中间计算结果放入磁盘,Spark采用内存存储中间计算结果,减少了迭代运算的磁盘IO
- 通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间
7.5 编程
7.5.1 Scala
Scala是函数式编程。
-
声明,无需指明类型,但要做初始化,推荐使用val
- val:常量
val num = 100- var:变量
-
常用类型:Byte、Char、Short、Int、Long、Float、Double、Boolean,都是类
-
类和对象
- class:类,不能使用static修饰符,需要new才能用
- object:对象,全是static的,可以有main函数
-
输入输出
print("hello world") println("hello world") val name = readLine() //读取一行输入 val age = readInt() //读取一个数字 -
条件语句
if(x>1){ count = 5 } else if(x>=0 && x<=1){ count = 4 } else{ count = 3 } -
循环语句
- for循环,
for(i <- 表达式),让变量i遍历表达式的所有值
for(i <- 1 to n){ r = r * i } val s = "Hello" var sum = 0 for(i <- 0 until s.length){ sum+=s(i) } for(ch <- "Hello"){ sum+=ch }- while循环
while(n > 0){ r = r * n n = n - 1 } - for循环,
-
函数,一般不使用return
- 完整写法,用return显示写明返回值,Unit一种表示无值的类型,用作不返回任何结果的方法
def addInt(a:Int, b:Int):Int = { var total:Int = a + b return total } def returnUnit():Unit = { println("ZST loves basketball !") }- 不写明返回值,程序会自行判断,最后一行代码的执行结果为返回值
def addInt(a:Int, b:Int) = { a+b }- 一行写法
def addInt(a:Int, b:Int) = a + b -
数组
val a=new Array[Int](7); println(a(0)) a(1)=1 for(i <- 0 until a.length-1){ println(a(i)) } -
映射,键值对的集合
val m=scala.collection.mutable.Map(("alan",1),("bob",2),("candy",3)) println(m("alan")) if(m.contains("bob")){ m("bob")=0 } -
元组,多元组,可以包含不同类型
val t = (1, 3.14, "Fred") println(t._1) println(t._2) println(t._3) -
Option,Option[T]是一个类型为T的可选值的容器,如果值存在,Option[T]就是一个Some[T];如果不存在,Option[T]就是对象None。而Java中的null不是对象,只是关键字
-
Scala和Java混合编译打包
mvn clean scala:compile compile package
7.5.2 Spark
RDD转换
-
filter,过滤,等同于创建一个类似SQL中的where子句,只保留
=>右边条件为true的数据def startsWithS(individual:String) = { individual.startsWith("S") //单词是否以S开头 } words.filter(word => startsWithS(word)) words.filter(word => word.startsWith("S")) data.filter(line => !line.equals(firstLine)) //删除表头即第一行 -
map,将函数应用于每一条记录
val wordCount=words.map(word => (word,1)) -
flatMap,将函数应用于每一条记录,结果展为多行,下面的语句如果用map,每行得到的是个数组
val words=input.flatMap(line => line.split(" "))
RDD动作
-
reduce,将所有记录规约为一个值,常用于求和,x和y是两条记录,
=>右边是对这两条记录的操作rdd.reduce((x, y) => x + y) -
count,返回RDD中记录的个数
-
first,返回第一行记录
-
take(n),返回前n行记录
-
collect,返回所有记录
-
foreach,对RDD中的每个记录使用给定的函数
foreach(println) //打印RDD中每一个元素
PairRDD转换(每一条记录是一个Key-Value对)
-
排序,Shuffle
rdd.sortByKey() 按键排序 rdd.sortBy(_._2) 按值排序,从小到大 rdd.sortBy(_._2, false) 按值排序,从大到小 -
groupByKey,Shuffle,对具有相同键的值进行分组
-
reduceByKey,Shuffle,合并具有相同键的值,x与y代表具有相同键的两个值,
=>右边为对两个值的操作reduceByKey((x,y) => (x + y)) reduceByKey((x,y) => (x + y), 10) //设定分区的数量 //计算每个键对应的平均值 (key,(value,1)) ._1是值总和,._2是数量总和,相除是平均值 rdd.mapValues(x => (x, 1)).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
-
提交Spark任务
安装目录/bin/spark-submit --class 主类所在包名.主类名 --master spark://IP地址:7077 jar包 参数1 参数2 参数n /opt/spark/bin/spark-submit --class pca.PCAMain --master spark://172.17.253.252:7077 /opt/jars/pca.jar cup95eff 15
7.6 调优
7.6.1 持久化(缓存)
中间结果RDD默认不在内存中保留,执行动作操作会重算所需要的所有RDD,有的RDD可能被重复计算了多次,
val result=input.map(x => x*x)
println(result.count()) //触发一次计算result
println(result.collect.mkString(",")) //触发一次计算result
可以先使用persist()对重复使用的RDD进行缓存(缓存并不触发计算),
val result=input.map(x => x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect.mkString(","))
persist()有MEMORY_ONLY,MEMORY_AND_DISK,DISK_ONLY等几种级别,其中MEMORY_ONLY相当于cache()
7.6.2 累加器
7.6.3 广播
8 Sqoop和Flume
8.1 Sqoop
Sqoop主要用于在关系型数据库和HDFS/Hive/HBase之间进行数据迁移,基于MapReduce实现面向大数据集的批量导入导出,将输入数据集分为N个切片,然后启动N个Map任务并行传输。
Sqoop 1向Hive/HBase中导入时,可以直接导入,从两者中导出时,需要将数据先存入HDFS;Sqoop 1只使用了Map。Sqoop 2从Hive/HBase中导入导出时,均需要将数据先存入HDFS;Sqoop 2使用了Map和Reduce。


8.2 Flume
8.2.1 原理
Flume是一个分布式海量数据采集、聚合和传输系统。Event是最小的数据传输单元;Agent是最小运行单元,包括Source、Channel和Sink三个基本组件,负责将外部数据源产生的数据以Event的形式传输到目的地。

- Source:负责对接各种外部数据源,将采集到的数据封装成Event,然后写入Channel
- Channel:Event暂存容器,负责保存Source发送的Event,直至被Sink成功读取(平衡Source采集、Sink读取的速度)
- Sink:负责从Channel读取Event,然后将其写入外部存储,或传输给下一阶段的Agent
一个Source可以接多个Channel,一个Channel可以接多个Sink,一个Sink只能从一个Channel中读数据,这是为了便于分类。

8.2.2 架构
- 单层架构,优点是:架构简单,使用方便,占用资源较少。缺点是:如果采集的数据源或Agent较多,将Event写入到HDFS会产生很多小文件,而HDFS对小文件不友好;外部存储升级维护或发生故障,需对采集层的所有Agent做处理,人力成本较高,系统稳定性较差;系统安全性较差(系统信息会对外暴露);数据源管理较混乱。

- 多层架构,优点是:避免产生过多小文件,提高系统稳定性和处理能力;各关联系统易于升级维护;对外不会暴露系统关键信息,降低攻击风险,显著提升安全性;各类日志数据分层处理,架构清晰,运维高效,降低人工误操作风险。缺点是:部署相对复杂,占用资源较多。

9 Kafka
Kafka是基于发布/订阅的分布式消息队列,可以用于缓存:将消息放入Kafka,可以不立即处理;解耦生产者和消费者;流量消峰:关键应用能够顶住访问峰值,不会因超出负荷而崩溃。消息持久化:采用时间复杂度O(1)的磁盘存储结构,即使TB级以上数据也能保证常数时间的访问速度;高吞吐:可以达到每秒数十万条消息的传输;高容错:多分区多副本;易扩展:新增机器,集群无需停机,自动感知;同时支持实时和离线数据处理。
9.1 架构
- Broker:Kafka的一个节点
- Topic:Topic是Kafka中同一类数据的集合(相当于数据库中的表),消息在Broker中按Topic进行分类,Producer将同一类数据写入同一个Topic,Consumer从同一个Topic中读取同类数据,Topic是逻辑概念,只需指定Topic就可以生产或消费数据,不必关心数据的物理存储
- Producer:向Broker发布消息的客户端
- Consumer:从Broker消费消息的客户端
- Consumer Group:每个Consumer都隶属于一个特定的CG,对于Topic中的某一消息,不同的CG可以重复读取该消息(组间共享),但一个CG中只能有一个Consumer可以读取该消息(组内互斥)

- Partition(分区):一个Topic可分为多个分区,相当于把一个数据集分成多份,分别存储不同的分区中,分区内消息有序,不保证Topic整体多个分区之间有序。Parition是物理概念,每个分区对应一个文件夹,存储分区的数据和索引文件。一个分区可以设置多个副本,副本存储在不同的Broker中

9.2 工作机制

Offset(偏移量)是定位分区中消息的顺序编号,用于在分区中唯一标识消息,推荐由Kafka来存储和维护Offset,即在Broker中记录和重置每个Comsumer读取分区消息的偏移量;也可以选择由Zookeeper来存储和维护,但效率会有一定影响。

分区是一个FIFO队列, 发布消息采用在队列尾部追加的方式,消费消息采用在队列头部顺序读取的方式。

每个Partition副本都是一个目录,目录中包含若干Segment文件,Segment文件是Kafka的最小数据存储单元,Segment文件由以消息在Partition中的起始偏移量命名的数据文件(*.log)和索引文件(*.index、*.timeindex)组成,索引是为了提高消息写入和查询速度。偏移量索引(*.index)的索引数据格式为<offset,position>,时间戳索引(*.timeindex)的索引数据格式为<timestamp,offset>,两者均为稀疏索引。

9.3 高可用
- 多分区多副本+Leader/Follower

一个Topic可以有多个分区,每个分区可以有多个副本,副本存储在不同的Broker中,从一个分区的多个副本中选举一个Partition Leader,由Leader负责读写,其他副本作为Follower从Leader同步消息(类似ZooKeeper)。
- 双层选举

(1)Controller Leader选举:每个Broker启动时都会创建一个Controller进程,通过Zookeeper,从Kafka集群中选举出一个Broker作为Controller Leader,Controller Leader负责管理分区和副本状态,避免分区副本直接在Zookeeper上注册Watcher和竞争创建临时Znode,导致Zookeeper集群负载过重。
(2)Partition Leader选举:Controller Leader负责Partition Leader的选举。
10 Docker
10.1 容器和虚拟机的区别

- 虚拟机:通过宿主机的软件模拟硬件的输入输出,然后让虚拟机的操作系统运行在该虚拟的硬件上,模拟硬件的软件称为hypervisor。虚拟机有其自己的内核、硬件,启动的时候需要先做开机自检、启动内核等等,速度很慢
-
容器:可以不模拟硬件的输入和输出,而直接使用宿主机的硬件和内核,因此速度提升很大。而只要隔离容器不让它看到主机的文件系统,进程系统,内存系统等等一系列,那么容器系统就很接近虚拟机了。Linux从内核版本3.10开始,支持隔离特性,主要使用Namespace、Cgroup、UnionFS等技术
- Namespace:主要用于访问隔离,用来让运行在同一个操作系统上的进程不会互相干扰,要做到的效果是如果某个 Namespace 中有进程在里面运行,它们只能看到该 Namespace 的信息,无法看到 Namespace 以外的东西,这些信息主要包括系统的hostname、可用网络资源、进程的关系、系统的用户信息、文件挂载、进程间怎么通信等等,如在容器中启动一个进程,在容器内的PID是1,在宿主机上可能是2198
- Cgroup(Control Group):主要用于资源限制,限制、记录和隔离进程组使用的物理资源(CPU、Memory、IO 等)
- UnionFS:联合文件系统,支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下,是Docker镜像的基础
10.2 Docker
本质是进程
10.2.1 镜像和容器
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。Docker镜像利用UnionFS进行分层存储,构建时,会一层层构建,前一层是后一层的基础,每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。分层存储的特征还使得镜像的复用、定制变的更为容易,甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。

最底层是bootfs(boot file system),主要包含内核和bootloader,其中内核是各个镜像共用宿主机的,bootloader主要是引导加载内核;再上一层是rootfs (root file system),根文件系统,相当于各种不同的发行版,主要包含/dev、/bin、/sbin、/etc、/lib 等标准目录和文件。再之上就可以添加一层层的只读层,如上图的emacs、Apache、jdk、tomcat等等。
容器是在镜像的基础上,在其上添加了一个可读可写的存储层。
10.2.2 操作
-
获取镜像,从镜像仓库Docker Hub中获取,18.04是标签
docker pull ubuntu:18.04 -
列出镜像
docker image ls -
删除镜像
docker image rm ubuntu:18.04 -
docker commit,在对容器的存储层进行改动后,使用该命令可以将容器的存储层保存下来成为镜像,即在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像
-
使用Dockerfile定制镜像,使用docker commit不透明且容易造成臃肿,Dockerfile是一个文本文件,其内包含了一条条的指令,每一条指令构建一层,是描述该层应当如何构建
FROM nginx RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.htmlFROM指定基础镜像,RUN执行命令,每一个 RUN 的行为,就是新建立一层,在其上执行这些命令,执行结束后,commit 这一层的修改,构成新的镜像
-
构建镜像,在Dockerfile所在目录使用该命令,-t用于指定新镜像的名称,.指定上下文路径
docker build -t nginx:v3 . -
启动容器,create为镜像分配文件系统并添加一个存储层,构成容器,start为容器创建一个进程隔离空间
docker create [--name 容器名] ubuntu:18.04 docker start/stop/restart 容器名/id以上两条命令相当于docker run,该命令首先检查本地是否存在指定的镜像,若不存在则从仓库中下载,然后在镜像上添加一个可读可写层,构成容器,然后分配网络,最后执行用户指定的应用程序,执行完毕后容器被终止,若最后不添加命令,则直接退出,
docker run ubuntu:18.04以下命令在输出后退出,
docker run ubuntu:18.04 /bin/echo "hello world"以下命令启动一个 bash 终端,允许用户进行交互,
docker run -it ubuntu:18.04 /bin/bash相关选项,bash命令要与-t及-i一起使用,可写作-it
-t 让Docker分配一个伪终端并绑定到容器的标准输入上 -i 让容器的标准输入保持打开 -d 让容器在后台运行而不是直接把执行命令的结果输出在当前宿主机下 -
进入正在运行的容器
docker attach 容器名/id -
在正在运行的容器中执行命令
docker exec 容器名/id 命令 -
查看所有容器
docker ps -a -
删除容器
docker rm 容器名/id -
创建网络,-d用于指定网络类型,在启动容器时可以用[–network 网络名]来连接到网络,同一网络中的容器就可以互相连接
docker network create -d bridge 网络名
10.2.3 三剑客
- docker-machine:用于在各种平台(如Windows)上快速创建具有docker服务的虚拟机
- docker-compose:用于对本地Docker容器集群的快速编排(多个容器相互配合),使用docker-compose.yml模板文件来定义一组相关联的service为一个project
- 服务(service):一个应用的容器
- 项目(project):由一组关联的应用容器组成的一个完整业务单元
- docker-swarm:用于解决多主机多个容器调度部署的问题
10.3 Kubernetes
容器编排工具(Docker的集群版)
11 其他框架
11.1 流计算
11.1.1 常见的流计算框架
- Storm(已经基本淘汰):分布式流计算框架
- Spark Streaming:微型批处理
- Flink:分布式流计算框架
11.2 ElasticSearch
ElasticSearch是分布式的搜索引擎,主要用于检索。
11.2.1 应用场景
- 文档数据库
- 日志分析与监控
- 舆情分析:高聚合率的统计分析,如热词跟踪
- 搜索引擎: 多条件模糊查询,语义查询,不指定列的全文搜索
11.2.2 数据模型
- Index相当于SQL中的Table,是一类数据,如为员工信息创建一个Index,或为商品信息创建一个Index
- Document相当于行,以JSON形式存储
- Field相当于列
- Mapping相当于表结构的定义
11.2.3 倒排索引
例如有两篇文档,文档1的内容为,
Tom lives in Shanghai, I live in Shanghai too.
文档2的内容为,
He once lived in Beijing.
先对文档进行分词,然后去除停用词,结果分别为,
[Tom] [live] [Shanghai] [i] [live] [Shanghai]
[He] [live] [Beijing]
根据分词结果,构建倒排索引如下,

这样,就能快速检索指定词(常常是一些关键词、热词)所在的文档。
11.2.4 分布式架构
主节点(MasterNode)负责管理集群变更,如增删节点、分配分片等,但不负责文档更新和搜索;数据节点(DataNode) 负责存储和管理数据,即文档的增删改查;路由节点(ClientNode)接收客户端的请求,根据集群的负载均衡进行协调。当一个Index较大时,可以切分成多个Shard(分片),然后分布到各节点中,Document根据哈希取模分配到不同的Shard中。Shard包括一个主Shard和零或多个副本Shard,副本越多,读能力越强,但会增加写的负载。
- 更新文档

图中高亮的P0、P1代表主Shard,R0、R1分别代表其副本Shard。客户端向Node1(路由节点)发送更新请求,路由节点通过id确定目标文档属于Shard0,由于Shard0的主分片P0在Node3上,所以将请求转发给Node3,Node3在主分片上完成文档更新后,将请求转发到Node1和Node2,完成副本Shard的数据同步,然后向Node1反馈结果,再由Node1向客户端反馈结果。
- 读取文档

客户端向Node1(路由节点)发送读请求,Node1通过id确定目标文档属于Shard0,并按照负载均衡的原则,将请求转发给Node2(此时,如果客户端未收到索引成功反馈,那么完成索引的文档可能存在于主分片上,还没同步到副本分片, 这时访问副本分片会报文档不存在;如果客户端收到反馈,那么文档在主分片和副本分片上都是可用的),Node2将目标文档返回给Node1,再由Node1返回给客户端。
12 总结
12.1 Hadoop整体框架
Hadoop的整体架构如下,HDFS为最底层的数据存储层;HBase为数据库,数据存储在HDFS上;MapReduce、Spark等计算框架可以直接访问HDFS,也可以通过HBase进行查询等;Hive在MapReduce和Spark之上,SQL语句被转换成MapReduce或Spark进行计算;ZooKeeper;Yarn
MapReduce和Spark都是通过Shuffle将Job切分为Stage,每个Stage有多个可以同时计算的Task,每个Task运行在Container/Executor上,这些Container/Executor分布在多个的节点上(每个节点上也可以有多个),这就是分布式计算。

12.2 Hadoop的运行模式
- 本地模式(Local/Standalone):不会启动NameNode、DataNode等守护进程,使用本地文件系统,主要用于开发和调试
- 伪分布式模式:用一台主机模拟多台机器,NameNode和DataNode这些守护进程运行在一台机器上
- 完全分布式模式:生成环境,NameNode和DataNode这些守护进程运行在集群(多台机器)上
- 高可用模式(HA):使用ZooKeeper来保证高可用
12.3 各种分区
- HDFS:分块(block)
- Map的输入:分片(split)
- Reduce的输入:分区(partition)
- Spark的输入:分区(partition)
- HBase:区域(region)